This is the second part of a two-part blog post documenting how to use DH Press to create digital oral history projects. Return to Part 1.
Workflow at a Glance
After you have completed your interviews, you can follow this general workflow for creating an oral history project in DH Press:
- Produce a clean, edited transcript
- Timestamp the transcript, either manually or using a timestamping tool
- Format the transcript for the DH Press Audio/Transcript Tool
- Load your audio files to SoundCloud, and/or your video files to YouTube
- Load all of your timestamped, formatted transcripts to the DH Press Media Library
- Create your data set
- Import your data into DH Press
- Configure your DH Press project and add any additional content to your website
Step 1. Create all Transcripts
In order to use the DH Press Audio/Transcript Tool to its fullest, you will need complete transcripts for each interview. Follow whatever process your organization uses to create and edit your transcripts.
If you do not have the capacity to create complete transcripts, you may consider transcribing the relevant sections of your interview, or possibly working with tape logs. However, this will limit the usability of those interviews in DH Press, as it will constrain your users’ ability to explore fully each interview.
Format
Transcripts should be saved as either Word files (.doc or .docx) or Plain Test (.txt) files. See Step 3 below for more details.
Step 2. Timestamp all Transcripts
Once you have a completed transcript, you will need to timestamp it. In other words, you will need to provide the corresponding times that match various moments in your transcript to the actual media file. For example:

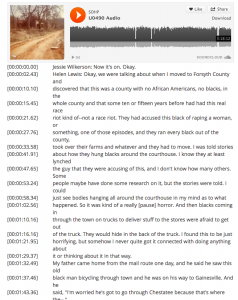
Example of a timestamped transcript
Each transcript that you plan to include in your DH Press project will need to be timestamped.
There are two ways you can develop timestamps, either by using a timestamping tool, or by producing your timestamps manually.
Automated Timestamping
There are some tools available that will produce a timestamped transcript for you. Essentially they allow you to feed your transcript and audio file into the tool, and the tool returns a timestamped transcript. We have used Docsoft:AV for this purpose. However, this is proprietary, and quite expensive, software. Docsoft:AV produces timestamps at short intervals, typically every few seconds. It is accurate down to the microsecond level. You may need to re-process your transcript several times in order to obtain accurate timestamps.
The Louie B. Nunn Center for Oral History at the University of Kentucky Libraries created OHMS: Oral History Metadata Synchonizer which may also be of use for timestamping.
Manual Timestamping
If you don’t have access to an automated timestamping tool, you can insert timestamps manually, either during the initial transcribing process, or after. In other words, you can manually type in your timestamps at whatever interval you choose. For instance, you may want to insert a timestamp at every question and response, or at even intervals, such as every two or five minutes. Timestamps can be inserted in the middle of sentences. The more timestamps you insert, the more control users will have to navigate, explore, and jump around in an interview.
When deciding how to timestamp your transcripts, you may need to balance the needs of your users against your own resources (time, labor, deadlines).
There are many free tools out there that can assist with your timestamping process. ExpressScribe is one such tool that allows you to slow down the audio to get a more precise timestamp. It supports timestamps to the microsecond level, and can be integrated with a foot pedal.
Timestamp Format
Regardless of which approach you take, each timestamp should be formatted accordingly:
[HH:MM:SS.MS]
That is: [Hour:Minute:Second.Microsecond]
Brackets are required at both the beginning and end of every timestamp. Each value (hour, minute, second, microsecond) should appear as a double digit. Use a zero as the first number when appropriate (03 instead of 3 seconds, for instance). Hours, minutes and seconds should be separated by colons (do not use extra spaces). Microseconds are optional; when used they should be separated with a period. Please note that you will need a concluding timestamp at the end of the transcript, indicating the end of the audio file.
- Example of a full timestamp: [01:11:03.94]
- Example of a timestamp without microsecond: [01:09:22]
- Example of a timestamp for an interview that is less than an hour: [00:39:43.73] or [00:39:43], which corresponds to thirty-nine minutes and forty-three seconds (and 73 microseconds).
Step 3. Format all Transcripts
All timestamped transcripts should be formatted according to the following specifications:
Placement of Timestamps
Each timestamps should be placed on a line by itself, with the corresponding text appearing below the timestamp. For example:
[00:30:09.83]
But I became sort of a good wife, and he wanted to go on to graduate school at [00:30:17.63]
the University of Virginia.
[00:30:18.63]
JW: Why did you get married?
[00:30:20.13]
HL: It was considered the thing to do. So I’m working in the governor’s office, [00:30:28.19]
he’s at Emory, and he would visit every weekend and of course my family liked
Speaker Names
The interviewer and interviewee’s names should be listed in full the first time each one speaks. Initials may be used each subsequent time. If you prefer, you may continue to use the full names each time, or just the last name. Adopt whatever approach is common among your organization or collaborators. Any of these formats will work in DH Press, but we recommend consistency within and across each transcript. For example:
[00:00:00.00]
Jessie Wilkerson: Now it’s on. Okay.
[00:00:02.43]
Helen Lewis: Okay, we were talking about when I moved to Forsyth County and
…
[00:02:36.89]
JW: Oh, goodness.
[00:02:37.89]
HL: That’s when I was in high school. So those were my experiences in Forsyth
Sentence Spacing
DH Press can only display text transcripts with a single space after periods. All double (or triple) spaces after periods should be eliminated. See why you should never use two spaces after a period. Likewise, only use single spacing between sentences/lines.
Here is an example of a complete timestamped transcript.
Additional Interview Metadata
No additional information (such as title, interview date, interview location, interviewer’s name) should appear on the transcript. That is, all header or metadata information should be stripped from the final transcript.
We recommend that you create a corresponding metadata text file or spreadsheet for this information, which might include the following fields:
- Interviewer(s)
- Interviewee(s)
- Interview Date
- Interview Location
- Transcriber(s)
- Notes
You may also need to record the filename of the audio/video file, and where it is being stored locally (e.g. on a hard drive, on a server, in a cloud-based site such as Dropbox, etc.).
File Format
In order for DH Press to display transcripts properly, you will need to convert each transcript to a plain text (Unicode UTF-8) file format.
Before doing that, we recommend that you remove any special formatting, such as:
- Bold or italics
- Special paragraph formatting, such as double spacing or hanging lines (note that double spacing between sentences may throw an error in the tool)
You can leave special characters (such as serif quotation marks, ampersands, tildes, accents, umlauts) intact.
When ready, re-save the file using the plain text file format. In Microsoft Word: Save as > Format (Plain Text) > Encoding (UTF-8). Once the save is completed, you will see a duplicate filename with a .txt file extension (in contrast to .doc or .docx). For example:
LachPam_transcript.docx
LachPam_transcript.txt
Alternatively, you can save the text file with a new filename.
You may continue working from the .docx file to create your data (see Step 6) but the .txt file is the one that will be loaded into DH Press (see Step 5).
We recommend that you double check your transcript formatting in a plain text editor (Windows: Notepad (built in) or Notepad++; Mac: TextEdit (built in) or TextWrangler) to ensure that there is no strange formatting in your document. You may need to manually edit the transcript to remove any potential formatting problems.
File Name
When naming your transcript file, we strongly recommend that you adhere to naming conventions for web files. Most importantly:
- Do not include spaces in your file name
- Good: PamLachTranscript or Pam_Lach_Transcript or Pam-Lach-Transcript
- Bad: Pam Lach Transcript
- Do not include any special characters in your file name, such as:
- Commas, apostrophes, quotation marks, accents, or ampersands
Step 4. Load all Digital Media Files to SoundCloud or YouTube
DH Press’s Audio/Transcript Tool works by linking your audio file to your transcript file, both of which would have been pre-loaded to the web.
All audio files will need to be loaded to SoundCloud in order for your project to work. Please consult SoundCloud’s documentation to learn how to upload your content. We recommend that you load your files using the mp3 format. Uploading WAV files will result in file compression/truncation, which can adversely impact performance in DH Press.
You will need to copy the URL for each individual audio file that you upload. Each URL will need to be included in the data file you will build for the project. Each audio file must have a unique URL.
To grab the URL, simply navigate to the file and copy the URL in the navigation bar. For example: https://soundcloud.com/sohp/u0490-audio. There is no need to grab either the Widget Code (the <iframe> code) or the WordPress Code. We recommend that you paste all URLs into a spreadsheet or Word document to keep track of all URLs. For example:
You can do the same for video files, but you’ll load those files to YouTube.
Step 5. Load all Transcripts into DH Press
Likewise, each timestamped transcript .txt file will need to be loaded to your DH Press Media Library. You can bulk load these files: WordPress Dashboard > Media Library > Add New and select all the files you want to load (you can also load these in one-by-one). As with your media files, you’ll need to copy the URL for each individual transcript. To do that, navigate to the Media Library and select the “View” option for each individual transcript.
You should add your transcript URLS to your tracking document:
The exact URL for your transcript will vary.
Step 6. Create all Data for DH Press Project
You are now ready to create the data for your DH Press project. This is the process whereby you transform the stories related in your oral histories into data (rows and columns in a spreadsheet) based on common themes. Project data are created outside of the DH Press environment and imported later. Please consult our Data Documentation for more information about required fields, supported data formats, and data collection tools available.
Essentially, the process of creating your data is an indexing project, similar to assigning tags to various segments of each interview. This allows you to describe various portions of an interview. Each chunk you describe becomes a row of data in your spreadsheet, which in turn, becomes a dot on the map. Each chunk has a starting point and an ending point, both of which correspond to the timestamps in your transcript. Make sure all timestamps in your data exactly match the timestamps in the transcript, or you will get error messages in DH Press.

This chunk of the transcript corresponds to a single row of data in the spreadsheet.
Determining a data model for your project can be tricky, especially if you are not accustomed to thinking about your work in data terms. Unfortunately, that is beyond the scope of this documentation. Email me if you would like to set up a brief consultation about your data.
Choosing a Data Collection Tool
Data may be gathered in a variety of ways, using a range of tools, but data sets can only be bulk imported into DH Press when formatted as comma-separated values (CSV) files. Using a spreadsheet that can output as CSV is probably the easiest way to create your data.
There are numerous spreadsheet tools available, including Microsoft Excel, Google Spreadsheets, Apple Numbers, or any other open source spreadsheet tool. Whatever spreadsheet tool you select, make sure it can export files as CSV.
*Mac users working in Excel must use the Windows Comma Separated (CSV) file format, or data will not successfully import into DH Press.
Fields Required for DH Press
Whatever data you want to represent in your digital oral history project, there are a few fields (spreadsheet columns) that are absolutely necessary. The following three columns should appear at the beginning of your data (Columns A, B and C, respectively), with an optional fourth column (Column D):
- csv_post_title
- csv_post_type
- project_id
- csv_post_post (optional)
Make sure all fields names are lowercased and that there are no hanging spaces at the end of the field name. Use only underscores in these field names. Please consult our data documentation for an explanation of each field, and their appropriate values.
You can also download a DH Press data template to assist you in your data collection. Note that the fourth column in the spreadsheet (csv_post_post) is optional.
Required Fields for Audio/Transcript Tool
In addition, you will need to create columns to capture all of the information about your interviews (interview metadata). This should include:
- Interviewee_name
- Interviewer_name
- Interview_location
- Interview_date
- Media_URL (SoundCloud or YouTube URL)*
- Transcript_URL (DH Press URL)
- Timestamp
The Timestamp column is critical for enabling users to jump around and explore an audio file and transcript. This column captures the starting point and ending point of the segment of the interview you are describing. This corresponds to the actual beginning and closing timestamp in the transcript. It should be formatted accordingly: starting point-ending point. For example: 00:00:02.43-00:03:05:66
*The current version of DH Press cannot support using SoundCloud and YouTube files interchangeably. If you are working with a mix of audio and video files, we recommend that you create two separate fields in your data: Audio_URL and Video_URL. Please note that we have not yet incorporated YouTube media files into the Audio/Transcript Tool but hope to do so soon.
Other Possible/Suggested Fields
Once you have established these eleven required fields, the rest is completely up to you and what you are trying to visualize in your project. You might think about recording common, overarching themes, or keywords, or other descriptive information. There is also space for extended narrative, interpretation, or analysis (we recommend using the csv_post_post field for this).
Note: in order to use the mapping tool (currently our only available visualization, or entry point), you will need a field for Latitude and Longitude. This can be represented as a single field (latitude,longitude) or as two distinct columns. Whichever way you prefer, make sure that Latitude is always listed first. DH Press uses the Decimal Degrees format (not the Degrees, Minutes, Seconds format), which can be obtained via Google Earth or Google Maps (or a similar program). To see latitude/longitude in Google Maps, enter the location address in the search bar, and then right click the map marker. Select What’s Here to display the latitude and longitude coordinates.
Whatever you decide, these columns can potentially be used to create distinct filters (“legends”) for your map, where unique values determine each marker’s appearance. For example, in the “Mapping the Long Women’s Movement,” markers all dealing with the women’s movement are purple, while markers related to education are blue.
Here is a segment of the data we collected for the Long Women’s Movement project:

An incomplete segment of Long Women’s Movement data.
Step 7. Import all Data into DH Press Project
Once you’ve completed and cleaned your data (checked for consistency), you should be ready to import your data into DH Press. Remember to add the appropriate project_id value to your spreadsheet prior to importation. Please consult our documentation to learn more about these processes.
There are some common mistakes that occur when importing data, including:
- ERROR: row(s) of data (e.g. “marker posts”) do not import (error message: Skipped N posts)
- CAUSE: missing unique “csv_post_title” value (Column A)
- ERROR: posts imported but not as Marker Posts
- CAUSE: missing “dhp-markers” value (Column B)
- ERROR: posts imported as Marker Posts but are “orphaned”
- CAUSE: missing or incorrect “project_id” value (Column C)
- markers will show up in Marker Library but will not show up when you try to configure your project (if none of your data fields show up, it means the Project ID was wrong)
Step 8. Configure DH Press Project
When you’re ready to create your DH Press project, please consult our DH Press documentation. You may also want to review our at-a-glance project creation workflow.
In particular, you’ll need to format the following “motes” accordingly:
Audio URL: configure as FILE data type
Transcript URL = configure as FILE data type
Timestamp = configure as TEXT data type
In addition to creating a Map Entry Point, you’ll need a second entry point “A/V Transcript.” This entry point should be added as the entry point in the modal. This should be the only entry point assigned in the modal.
Once the project is configured, you should be ready to share it with your audience. Because DH Press is integrated into WordPress, you can also create any number of other pages related to your project, your staff, your sponsoring organization, or other similar projects.
Using non-English Languages
As noted earlier in this documentation, preliminary testing suggests that non-English interviews can be used in DH Press, provided the transcripts are formatted as Plain Text, encoded as Unicode (UTF-8). To date, we have only tested Spanish. To see this in action, visit Digital Portobelo: Art + Scholarship + Cultural Preservation.
Moving Beyond Oral History
We are beginning to think about how the DH Press Audio/Transcript Tool might be adapted more broadly beyond digital oral history projects. In theory, any sort of streaming multimedia could be used, provided there is a supporting .txt file with some sort of timestamps to assist with navigation, i.e. an index with the appropriate metadata. One potential adopter suggested using the tool as a bridge between recorded music and sheet music, assuming the sheet music could be converted to a plain text file. You could also use the tool for documentaries and other films.
We are only just beginning to explore the possibilities, so stay tuned for future experimentation.
Need Help?
Have an idea for an extension to the Audio/Transcript Tool? Or need help getting your project started? Contact me!
Return to Part 1.